Ease of building Patent Search Platform now with Google Patents Public Datasets
Now patent data got cheaper with the launch of new Patents Public Datasets by Google based on the company’s owned enterprise data warehouse BigQuery, which gathers openly available, associated database tables for exact investigation of the worldwide patent framework.
Enterprises often keep up accumulations of private information about patents, for example internal tagging system that compares to particular product offerings, and they need to associate that data with other patent datasets to create reports and examine speculation zones. Now organizations can consolidate their private information with open and paid datasets to ask “what are my active patents and pending patent applications?”, “which of my patents in what technological areas are lapsing soon?” or “what are the best organizations that refer to the patents I’ve labeled with [widget #57]?”.
Patent data availability is basis for analyzing new patents, illuminating open approach choices, overseeing corporate interest in protected innovation, and advancing future logical advancement. The developing number of accessible patent information sources implies specialists frequently invest more energy downloading, parsing, stacking, matching up and overseeing nearby databases than leading examination. With these new datasets, specialists and organizations can get to the information they require from different sources in a single place, in this way investing more energy in examination than data preparation.
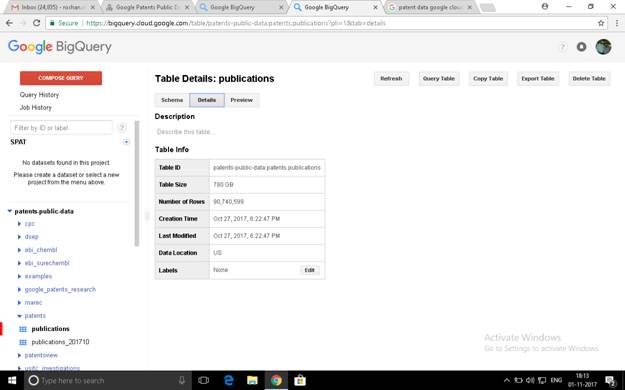
| Table ID | patents-public-data:patents.publications |
| Table Size | 780 GB |
| Number of Rows | 90,740,599 |
| Creation Time | Oct 27, 2017, 6:22:47 PM |
| Last Modified | Oct 27, 2017, 6:22:47 PM |
| Data Location | US |
| Labels | NoneEdit |
Table Details: publications
Refresh Query Table Copy Table Export Table Delete Table
| publication_number | STRING | NULLABLE | Patent publication number (DOCDB compatible), eg: ‘US-7650331-B1’ |
| application_number | STRING | NULLABLE | Patent application number (DOCDB compatible), eg: ‘US-87124404-A’. This may not always be set. |
| country_code | STRING | NULLABLE | Country code, eg: ‘US’, ‘EP’, etc |
| kind_code | STRING | NULLABLE | Kind code, indicating application, grant, search report, correction, etc. These are different for each country. |
| application_kind | STRING | NULLABLE | High-level kind of the application: A=patent; U=utility; P=provision; W= PCT; F=design; T=translation. |
| application_number_formatted | STRING | NULLABLE | Application number, formatted to the patent office format where possible. |
| pct_number | STRING | NULLABLE | PCT number for this application if it was part of a PCT filing, eg: ‘PCT/EP2008/062623’. |
| family_id | STRING | NULLABLE | Family ID (simple family). Grouping on family ID will return all publications associated with a simple patent family (all publications share the same priority claims). |
| title_localized | RECORD | REPEATED | The publication titles in different languages |
| title_localized.text | STRING | NULLABLE | Localized text |
| title_localized.language | STRING | NULLABLE | Two-letter language code for this text |
| abstract_localized | RECORD | REPEATED | The publication abstracts in different languages |
| abstract_localized.text | STRING | NULLABLE | Localized text |
| abstract_localized.language | STRING | NULLABLE | Two-letter language code for this text |
| claims_localized | RECORD | REPEATED | For US publications only, the claims |
| claims_localized.text | STRING | NULLABLE | Localized text |
| claims_localized.language | STRING | NULLABLE | Two-letter language code for this text |
| description_localized | RECORD | REPEATED | For US publications only, the description, limited to the first 9 megabytes |
| description_localized.text | STRING | NULLABLE | Localized text |
| description_localized.language | STRING | NULLABLE | Two-letter language code for this text |
| publication_date | INTEGER | NULLABLE | The publication date. |
| filing_date | INTEGER | NULLABLE | The filing date. |
| grant_date | INTEGER | NULLABLE | The grant date, or 0 if not granted. |
| priority_date | INTEGER | NULLABLE | The earliest priority date from the priority claims, or the filing date. |
| priority_claim | RECORD | REPEATED | The application numbers of the priority claims of this publication. |
| priority_claim.publication_number | STRING | NULLABLE | Same as [publication_number] |
| priority_claim.application_number | STRING | NULLABLE | Same as [application_number] |
| priority_claim.npl_text | STRING | NULLABLE | Free-text citation (non-patent literature, etc). |
| priority_claim.type | STRING | NULLABLE | The type of reference (see parent field for values). |
| priority_claim.category | STRING | NULLABLE | The category of reference (see parent field for values). |
| priority_claim.filing_date | INTEGER | NULLABLE | The filing date. |
| inventor | STRING | REPEATED | The inventors. |
| inventor_harmonized | RECORD | REPEATED | The harmonized inventors and their countries. |
| inventor_harmonized.name | STRING | NULLABLE | Name |
| inventor_harmonized.country_code | STRING | NULLABLE | The two-letter country code |
| assignee | STRING | REPEATED | The assignees/applicants. |
| assignee_harmonized | RECORD | REPEATED | The harmonized assignees and their countries. |
| assignee_harmonized.name | STRING | NULLABLE | Name |
| assignee_harmonized.country_code | STRING | NULLABLE | The two-letter country code |
| examiner | RECORD | REPEATED | The examiner of this publication and their countries. |
| examiner.name | STRING | NULLABLE | Name |
| examiner.department | STRING | NULLABLE | The examiner’s department |
| examiner.level | STRING | NULLABLE | The examiner’s level |
| uspc | RECORD | REPEATED | The US Patent Classification (USPC) codes. |
| uspc.code | STRING | NULLABLE | Classification code |
| uspc.inventive | BOOLEAN | NULLABLE | Is this classification inventive/main? |
| uspc.first | BOOLEAN | NULLABLE | Is this classification the first/primary? |
| uspc.tree | STRING | REPEATED | The full classification tree from the root to this code |
| ipc | RECORD | REPEATED | The International Patent Classification (IPC) codes. |
| ipc.code | STRING | NULLABLE | Classification code |
| ipc.inventive | BOOLEAN | NULLABLE | Is this classification inventive/main? |
| ipc.first | BOOLEAN | NULLABLE | Is this classification the first/primary? |
| ipc.tree | STRING | REPEATED | The full classification tree from the root to this code |
| cpc | RECORD | REPEATED | The Cooperative Patent Classification (CPC) codes. |
| cpc.code | STRING | NULLABLE | Classification code |
| cpc.inventive | BOOLEAN | NULLABLE | Is this classification inventive/main? |
| cpc.first | BOOLEAN | NULLABLE | Is this classification the first/primary? |
| cpc.tree | STRING | REPEATED | The full classification tree from the root to this code |
| fi | RECORD | REPEATED | The FI classification codes. |
| fi.code | STRING | NULLABLE | Classification code |
| fi.inventive | BOOLEAN | NULLABLE | Is this classification inventive/main? |
| fi.first | BOOLEAN | NULLABLE | Is this classification the first/primary? |
| fi.tree | STRING | REPEATED | The full classification tree from the root to this code |
| fterm | RECORD | REPEATED | The F-term classification codes. |
| fterm.code | STRING | NULLABLE | Classification code |
| fterm.inventive | BOOLEAN | NULLABLE | Is this classification inventive/main? |
| fterm.first | BOOLEAN | NULLABLE | Is this classification the first/primary? |
| fterm.tree | STRING | REPEATED | The full classification tree from the root to this code |
| citation | RECORD | REPEATED | The citations of this publication. Category is one of {CH2 = Chapter 2; SUP = Supplementary search report ; ISR = International search report ; SEA = Search report; APP = Applicant; EXA = Examiner; OPP = Opposition; 115 = article 115; PRS = Pre-grant pre-search; APL = Appealed; FOP = Filed opposition}, Type is one of {A = technological background; D = document cited in application; E = earlier patent document; 1 = document cited for other reasons; O = Non-written disclosure; P = Intermediate document; T = theory or principle; X = relevant if taken alone; Y = relevant if combined with other documents} |
| citation.publication_number | STRING | NULLABLE | Same as [publication_number] |
| citation.application_number | STRING | NULLABLE | Same as [application_number] |
| citation.npl_text | STRING | NULLABLE | Free-text citation (non-patent literature, etc). |
| citation.type | STRING | NULLABLE | The type of reference (see parent field for values). |
| citation.category | STRING | NULLABLE | The category of reference (see parent field for values). |
| citation.filing_date | INTEGER | NULLABLE | The filing date. |
| entity_status | STRING | NULLABLE | The USPTO entity status (large, small). |
| art_unit | STRING | NULLABLE | The USPTO art unit performing the examination (2159, etc). |
These datasets incorporates Google Patents Public Data table containing worldwide bibliographic information on more than 90 million patent publications from 17 countries and US full text, provided by IFI CLAIMS Patent Services. Along with this Google is also providing a Google Patents Research Data table containing English machine translations for all titles and abstracts from Google Translate, similarity vectors, extracted top terms, and more. Common research datasets from patents, chemistry, and litigation have also been uploaded. Users can get to data gathered by different analysts and patent information suppliers in a similar database, and blend them with private information to create reports or research queries with the full opportunity of SQL, without setting up their very own database.
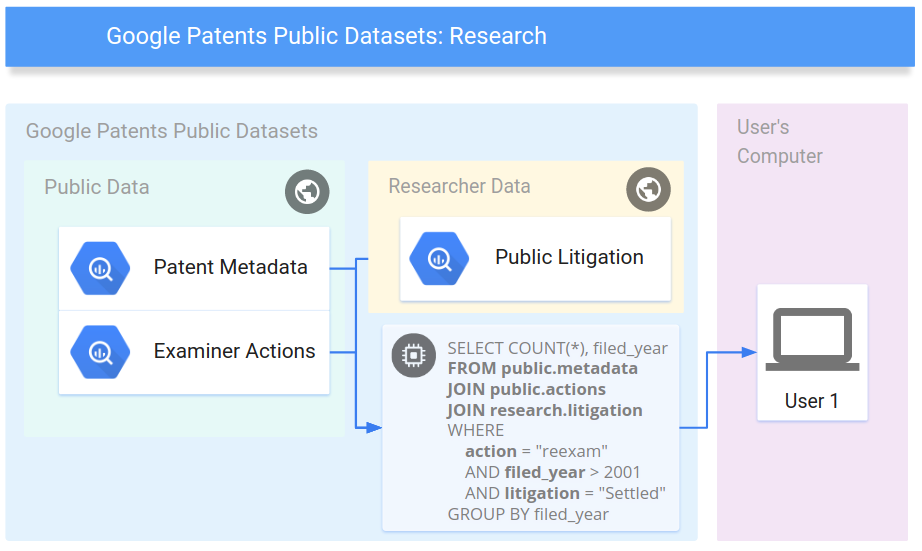
Commercial Data providers are also making their patent data available for purchase in BigQuery, starting with IFI CLAIMS Patent Data Enrichments including legal status information and standardized assignee names. Accessing these datasets through BigQuery gives users an up-to-date database managed by data providers, so users get the flexibility of a database without the engineering cost of maintaining one. Getting to these datasets through BigQuery surrenders clients a to-date database oversaw by information suppliers, so clients get the adaptability of a database without the designing expense of looking after one.
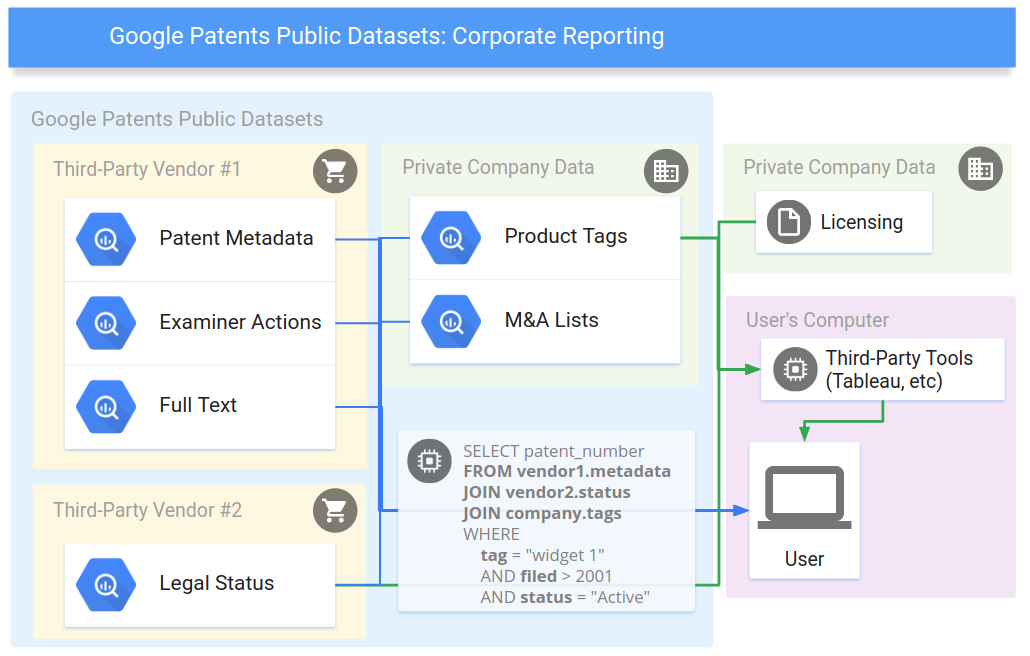
Several third party tools such as Tableau and Looker that can access BigQuery can also be employed which provide much easier interface for accessing database than SQL. For corporate having classified data that cannot leave their network, some of these tools can be used to fetch from the BigQuery and process that in conjunction to sensitive data.
BigQuery for Data Providers
For data providers, BigQuery is an extraordinary approach to pitch information in a right away helpful configuration to clients. The commonplace choices for information dissemination are either in bulk format through CSV/XML downloads, or through a web interface, yet both have drawbacks. Bulk format permit adaptability to the detriment of the client programming and keeping up their own databases, while web interfaces are anything but difficult to get to, however can’t undoubtedly be reached out with new paid or private wellsprings of information, and have a settled arrangement of conceivable approaches to question and show the information. Presently clients can get a similar adaptability of a database with the simple access of a web interface to associate private information and show it in dashboards and other visualization tools.